Aquestes són les diapositives de la presentació de Cassandra que vaig fer al SudoersBCN la setmana passada. Crítiques, comentaris i correccions seran benvingudes!
Cassandra – Errors freqüents
Des que treballo amb Cassandra he estat apuntant quins errors provocats per la inexperiència hem comés, per tal de no repetir-los. No en parlava gaire perquè algun d’ells em feia veritable vergonya 😀 Però fa poc he vist un video on també parlaven dels errors freqüents amb Cassandra, i hi sortien gairebé tots! El que m’hagués estalviat si hagués existit aquest vídeo quan vaig començar… aix! Però vaja, ara que veig que no som uns negats, sinò que equivocar-se forma part de l’aprenentatge de Cassandra, ja no em fa vergonya, així que aprofitaré el moment per explicar tots els errors, per si a algú altre li pot servir d’ajuda:
Error #1- Fer servir SAN o RAID 1/10/5
Aquests sistemes solucionen problemes inexistents, ja que Cassandra està desenvolupat per aguantar errors en els seus nodes. Per suposat podem afegir una altra capa d’alta disponibilitat en forma de SAN o RAID, però segurament serà més car i menys efectiu que fer-ho afegint més nodes de Cassandra. A més, en el cas de la SAN, si fem que tots els nodes escriguin a la cabina, estem afegint un Single Point of Failure que abans no teniem. Més encara, les dades a Cassandra s’escriuen a diversos servidors alhora, el que significa que processos interns com les compactions les fan tots alhora. Cassandra intenta treure el màxim rendiment possible a la I/O assumint que els discos son propis (com és normal), i el resultat és tots els servidors exprimint la SAN, que no dòna l’abast coordinant les escriptures, i clar, el seu rendiment (i per tant, el del nostre cluster) es veu greument afectat. No només no millorarà el rendiment del nostre cluster amb una SAN, sinò que molt probablement empitjorarà, i amb un cost força elevat. Evidentment pots posar una cabina prou potent com perquè ho pugui suportar, però per la meitat de diners pots millorar el cassandra amb la “Cassandra’s way”: fent servir discos locals, i si volem fer RAID, que sigui RAID0. El cassandra ja és a prova d’errors, deixem que ell mateix faci la seva feina.
Error #2- Posar un load balancer a davant dels Cassandra.
En principi sembla una bona idea: garantim que la càrrega es distribueix i, si un servidor cau, el load balancer el marcarà com a caigut i no li enviarà més connexions fins que es recuperi. Això ja ho tenim els servidors web, i va molt bé, oi? ERROR!! Tornem al mateix que abans: Aquest problema no existeix amb Cassandra. Les dades ja estan distribuides homogèniament entre tots els servidors, i els clients d’alt nivell (com Hector, Astyanax o pycassa) ja s’encarreguen de repartir les lectures i marcar-los quan estan caiguts. A més, afegint un load balancer afegim un Single Point of failure al sistema, quan abans no el tenia, consumim més recursos i encarim l’arquitectura. Fins i tot ens podem trobar que el propi balancejador sigui el coll d’ampolla del nostre sistema, portant més problemes on no els hi havia. El cassandra ja equilibra la càrrega, deixem que ell mateix faci la seva feina.
Error #3- Posar CommitLog i SSTables al mateix disc (no aplicable a discos SSD)
El CommitLog s’està escrivint contínuament de manera seqüencial. Si les SSTables s’han de llegir des del mateix disc, cada lectura molestarà l’escriptura del CommitLog, ja que perdrem la seqüencialitat, el disc haurà de fer seeks, i s’alentirà el procés d’escriptura (recordem que el que limita la velocitat d’escriptura a Cassandra és el que es triga a escriure el CommitLog, perquè la resta es fa en memòria). El CommitLog no necessita gaire espai, però es veu molt afectat pel seek time. A la nostra feina ho menyspreàvem pensant que seria poca la diferència de tenir-ho junt o separat… pero provant en el nostre cluster, on els servidors tenien una càrrega de 7-7.5, vam baixar a 4.5-5 només amb aquest canvi. La nostra cara? Boca oberta primer i facepalm després. Evidentment això no es aplicable a discos SSD on no hi ha seek time.
Error #4- Oblidar instal·lar la JNA (Java Native Access)
Què passa en aquesta màquina on els snapshots triguen més del normal a fer-se? Per què aquest node està més carregat que la resta? Revisa els teus manifests de puppet, perquè amb un 99% de possibilitats no has posat la JNA. La JNA (Java Native Access) fa que la màquina virtual de java pugui interactuar amb els sistemes de fitxers de forma nativa a través del sistema operatiu, i no amb llibreries java que son més lentes e ineficients. D’aquesta manera, interactuar amb fitxers resulta molt més ràpid, i es nota sobretot a l’hora de fer els snapshots. La instal·lació és molt senzilla, i les conseqüències de no instal·lar-la son greus.
Error #5 – No pujar el limit de 1024 file descriptors per Cassandra
Cassandra funciona amb molts sockets i fitxers oberts (hi ha moltes SSTables!), i 1024 (el límit màxim de fitxers per defecte a linux) se’ls acaba força ràpid. És probable que mentre estàs a un entorn de test o d’integració amb poca càrrega no te n’adonis. I també es probable que a producció comencis sense problemes. Però a mesura que van escrivint-se SSTables el número de fitxers oberts va creixent, i quan arribi al màxim el node caurà d’una manera molt lletja, i és probable que arrossegui amb ell a la resta de nodes del cluster. Sobretot, recorda afegir la modificació del limits.conf al teu manifest de puppet!!
Error #6- Posar un tamany de javaHeap superior a 8GB
Tens una màquina amb 64GB de RAM (ole tú!) i penses que, per aprofitar-la, podries donar més memòria al Cassandra, O tens errors de OutOfMemoryError, o et sembla que es fa GarbageCollection massa sovint, o per algún motiu creus que és bona idea pujar la memòria destinada al Heap, i augmentes el javaHeap al cassandra-env.sh. Però no oblidem que el proces de GarbageCollection es força costós, i la seva afectació al cluster augmenta exponencialment amb la quantitat de memòria per alliberar. Per tant, el recomanable son 4-8GB pel javaHeap, i en alguns casos una mica més, fins a 12GB, però només si sabem el que fem i tenim un objectiu amb això. Més de 16GB no s’haurien de posar en cap cas.
Si el que vols es aprofitar aquesta memòria, no et preocupis, Cassandra acabarà aprofitant-la com a page caché del SO.
Error #7- Fer servir els discs Amazon EBS
Els discs EBS d’Amazon tenen un rendiment dolent. Els venen molt bé, però la realitat es que la I/O és molt variable, i podem tenir llargues estones amb una latència molt alta, que ens mati el cluster. És millor fer servir els discos efímers de EC2 que tenen un rendiment més fiable. Sí, si la màquina es mor o l’hem de reiniciar, perdrem les dades d’aquest node i l’haurem de reconstruir… però per això està el nodetool rebuild. I sí, si cau tota la zona on tenim el nostre cluster, haurem de començar de zero, i això es molt arriscat, però si estàs fent servir aws segur que tens els snapshots de les màquinas i de les dades de Cassandra a Amazon S3, i restaurar-les serà ràpid (el Priam de Netflix t’ajudarà a fer-ho). Més informació al respecte.
I aquests són els errors que nosaltres ens hem trobat. Si has llegit això ABANS de començar amb cassandra, t’has estalviat uns quants maldecaps! 😀
Monitoritzant cassandra, dades rellevants que s’han de vigilar (i com enviar-les a graphite)
Segons els anteriors posts ja sabem com instal·lar cassandra i tunejar-lo mínimament Però no n’hi ha prou, perquè per posar-ho en un entorn productiu hem de poder garantir que el cassandra funciona correctament, i tenir alertes si no ho fa. Per això hem d’integrar-ho al nostre sistema de monitorització, ja sigui Nagios, Zabbix, Zenoss, Graphite, el que sigui. El que farem ara és identificar tots els punts que han d’estar vigilats per detectar possibles incidències al nostre clúster.
D’entrada voldrem assegurar-nos que la màquina disposa de recursos suficients i que el servei està en marxa i escoltant. Per mesurar els recursos ja vam veure el script que feia la monitorització bàsica d’un sistema linux. Per mirar si el procés està en marxa podem fer el típic /etc/init.d/cassandra status si hem instal·lat el script init.d, o “ps uax|grep CassandraDaemon|grep -v grep” si no ho hem fet. Per mirar si els ports que toquen estan escoltant, podem fer localment un netstat per cadascun dels dos: 7000 pel gossip (netstat -l –numeric-ports|grep “:7000 “) i 9160 pel thrift (netstat -l –numeric-ports|grep “:9160 “) o el mateix amb un netcat (que pot ser local o remot) nc -z -w 3
Però el cassandra és molt gran i té molts paràmetres configurables, i no és fàcil saber per què falla quan falla. I també estaria be poder predir que està a punt de passar alguna cosa greu abans que passi. Per tot això volem més dades, dades útils que ens facilitin diagnosticar problemes, veure que està passant internament i trobar quins paràmetres es poden tocar per optimitzar el seu funcionament. Aquestes dades les trobarem a la consola JMX de cassandra.
Hi ha varies maneres de connectar-nos a aquesta consola. La típica es amb el jconsole, i datastax ens ofereix el opscenter, però normalment voldrem incorporar aquestes dades al nostre propi sistema de monitorització. Hi ha gent que ha desenvolupat un pont entre el jmx i altres sistemes (munin, per exemple, a https://github.com/tcurdt/jmx2munin, o snmp amb https://github.com/tcurdt/jmx2snmp o appdynamics). A mi m’interessava integrar-ho amb graphite, per tant necessitava accedir a aquestes dades des de la consola. Amb el nodetool ja podia fer algunes coses (tpstats, cfstats, netstats, info, etc) però no totes, i a més tantes crides carregaves massa el sistema pel meu gust. Aleshores vaig descobrir mx4j, que és un pont que agafa les dades de la jmx i les serveix per HTTP, és a dir, posant-les a l’abast del nostre curl, on hi tenim fàcil l’accés. Perfecte! Just el que necessitava!
La instal·lació es senzilla (http://wiki.apache.org/cassandra/Operations#Monitoring_with_MX4J), només s’ha de descarregar el jar, posar-lo a la carpeta “lib” de cassandra i reiniciar. Normalment serà tan senzill com:
wget "http://downloads.sourceforge.net/project/mx4j/MX4J%20Binary/3.0.2/mx4j-3.0.2.tar.gz"
tar zxf mx4j-3.0.2.tar.gz
mv mx4j-3.0.2/lib/mx4j-tools.jar /opt/cassandra/lib/
/etc/init.d/cassandra restart
Un cop reiniciat el cassandra, ja podrem accedir al mx4j al port 8081 des del nostre navegador.
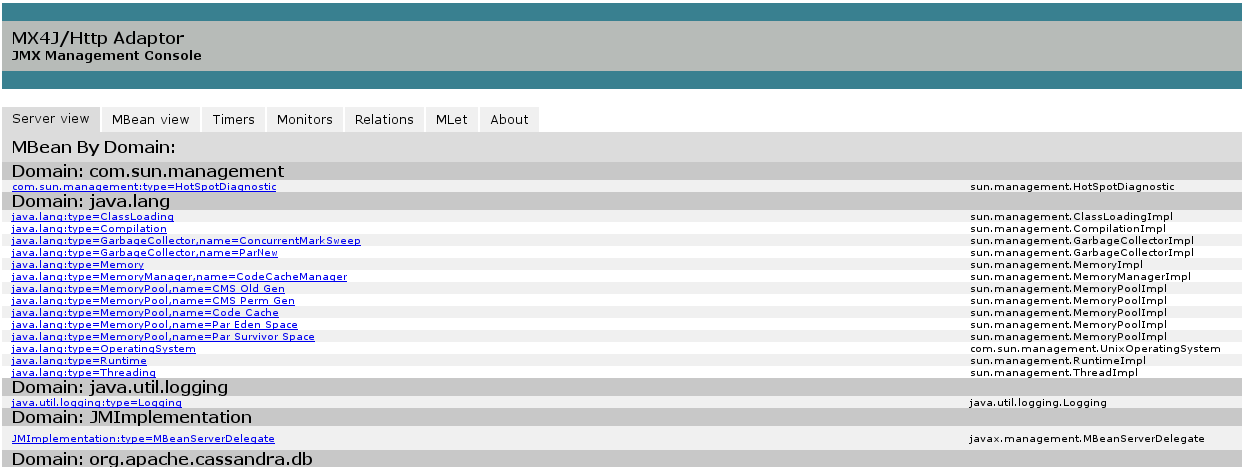
Trobarem que hi ha moltes MOLTES dades, i que moltes d’elles no sabem què signifiquen (ho sento, no sóc desenvolupador java, hi ha moltes coses que se m’escapen :P). Tenim una descripció de moltes de les mètriques a la documentació de cassandra i d’aquí hem de destriar quines d’aquestes dades ens interessen. Vaig llegir a uns quants blogs (mireu la bibliografia al final) i finalment vaig decidir que les dades que interessen (i que es poden recollir fàcilment) són les següents:
- Tasques en ReadStage, MutationStage, GossipStage
- Tasques de compactació
- Latència
- Ús de memoria Heap i NoHeap
- Número de GarbageCollections
- Numero de connexions
- Dades a per cada ColumnFamily
Amb aquests valors podem mesurar l’activitat de cada servidor, mesurant el número d’operacions que realitza. Els tres tipus d’operacions diferents son lectura, modificació i “gossip” (comunicació inter-nodes) . D’aquí recollirem el total de tasques completades (CompletedTasks) on podrem veure quantes tasques per minut es realitzen les tasques actives (ActiveTasks) on podrem veure en quantes tasques alhora està treballant el node, i les tasques pendents (PendingTasks) on podrem veure la cua de missatges que queden per fer. Amb això podrem veure moltes coses: per exemple si el numero de “PendingTasks” creix de manera ininterrompuda pot ser que el nostre node rep més peticions de les que pot processar, o també pot ser que ens haguem quedat sense espai en disc i, en no poder escriure al commitlog, les estigui acumulant (sigui com sigui, si aquesta mètrica puja, alguna cosa dolenta està passant). Si veiem que la carrega dels nostres servidors ha augmentat i també veiem que les CompletedTasks ho ha fet, significa que aquest augment es “normal”.
Aquestes dades les podem trobar a
http://$host:8081/mbean?objectname=org.apache.cassandra.request%3Atype%3DReadStage
http://$host:8081/mbean?objectname=org.apache.cassandra.request%3Atype%3DMutationStage
http://$host:8081/mbean?objectname=org.apache.cassandra.internal%3Atype%3DGossipStage
Normalment estan relacionades amb l’activitat del clúster. Si hi ha moltes escriptures, normalment es dispararan compactacions. D’aquí recollirem quantes tasques de compactació hi ha pendents (PendingTasks) i completades (CompletedTasks), per veure quantes es fan i si s’acumulen. Per exemple, si ens trobem que algun server està molt carregat, i la cua de compactació és molt llarga, haurem de valorar treure-li prioritat a les mateixes (nodetool setcompactionthroughput 1), o si veiem que la cua no para de créixer valorarem fer-li un disable del thrift (nodetool disablethrift) perquè no li arribin peticions noves i donar-li prioritat màxima a les compactacions perquè les acabi com més aviat millor (nodetool setcompactionthroughput 999). Aquestes mètriques també ens ajudaran a saber quan ha acabat un repair (ara per fi hi ha un indicador de progrés de repair disponible, a partir de la v1.1.9 i la 1.2.2), o un scrub/rebuild, o upgradesstables, etc. En qualsevol cas, si aquests valors són diferents de zero molt sovint, tindrem motius de preocupació. L’enllaç:
http://$host:8081/mbean?objectname=org.apache.cassandra.db%3Atype%3DCompactionManager
Amb aquest valor recollirem la latència que experimenten les operacions. Voldrem que aquest valor sigui el més petit possible, i si augmenta sense motiu haurem d’investigar per què. Disposem de la mesura de tres tipus de latència per diferents operacions: Range (RecentRangeLatencyMicros), Read (RecentReadLatencyMicros) i Write (RecentWriteLatencyMicros).
http://$host:8081/mbean?objectname=org.apache.cassandra.db%3Atype%3DStorageProxy
Per veure quanta memòria té disponible la màquina virtual de Java per treballar i quanta ocupada. Aquí recollirem HeapMemoryUsage i NoHeapMemoryUsage.
http://$host:8081/mbean?objectname=java.lang%3Atype%3DMemory -s
Aquí prendrem mesures del número de GarbageCollections que es fan al sistema. Això està relacionat amb el valor anterior, perquè cada cop que es faci el GarbageCollection s’alliberarà memòria. Ens servira per diagnosticar, per exemple, quan qualsevol procés java fa garbage collection molt sovint i acaba dedicant més temps a aquesta tasca que a la seva principal. Haurem de controlar la freqüència de les GC (ConcurrentMarkSweep). Si és massa freqüent, potser hem de destinar més memòria al nostre java. En qualsevol cas, voldrem que aquest valor sigui el més petit possible.
http://$host:8081/mbean?objectname=java.lang%3Atype%3DGarbageCollector%2Cname%3DConcurrentMarkSweep
Fora de la JMX també hi ha coses interessants
Amb això volem saber quantes connexions concurrents està servint el Cassandra. Així en cas de creixement de la càrrega al cassandra, podrem veure si es correspon amb un creixement en el número d’usuaris. Si la nostra aplicació no augmenta el número d’usuaris però el cassandra si que augmenta en el número de connexions, significa que hi ha alguna cosa que no funciona correctament (les peticions es processen més lentament, per exemple). Si veiem que el número de connexions de cassandra augmenta, i també ho fa el número d’usuaris de la nostra aplicació, aleshores l’augment es “normal” i haurem de millorar el Cassandra (donant-hi recursos o tunejant la configuració) per solucionar-ho. És una dada molt útil. Tot i que es podria millorar, estaria molt be que poguéssim veure quines transaccions està fent el cassandra (com un show processlist de mysql ) per poder veure si hi ha alguna petició mal construïda o que es pugui millorar. Però donades les característiques de Cassandra, això sembla bastant inviable, així que ens conformarem amb el número de connexions.. Vaig demanar a la llista de cassandra-users si hi havia alguna manera d’aconseguir-ho i em van dir que no, però que semblava una cosa interessant perquè es demanava força sovint, i per això van crear un ticket als desenvolupadors. Algun dia ho implementaran, espero, i podrem consultar aquest valor via JMX. Mentrestant, la única via que tenim es el netstat:
connections=netstat -tn|grep ESTABLISHED|awk '{print $4}'|grep 9160|wc -l
Per treure més suc al Cassandra també és recomanable analitzar dades per cada ColumnFamily. Així podrem veure el tamany, l’activitat, la taxa d’èxit que té la caché, quins indexs secundaris tenen… Però això són moltes peticions al mx4j (unes 21 per cada column family, a mi em surten gairebé 2000 peticions HTTP!), i la informació no varia tan sovint, així que per ara no recolliré aquesta informació, i quan ho faci la recolliré cada cinc minuts o cada quart d’hora per no sobrecarregar el cassandra amb la monitorització, per tant la posaré en un script apart.
I bé, tot això són les parts interessants de monitoritzar de cassandra. Per recollir tota aquesta informació vaig fer un script que podeu trobar al meu perfil github, amb el nom de cassandra-monitoring que es connectarà al mx4j dels servidors i traurà aquesta informació (excepte les connexions establertes, que per fer-ho necessita fer un netstat). Tota la informació que hem descrit, la recollirà i la posarà en una cadena de text (“data“) que després enviarà al graphite.
Aquí el teniu:
#!/bin/bash
# WARNING - ATENCIO
# This script requires mx4j to be installed on cassandra monitored nodes. For more instructions visit:
# Aquest script necessita que el mx4j estigui instal·lat als nodes monitoritzats. Per mes instruccions visita:
# http://wiki.apache.org/cassandra/Operations#Monitoring_with_MX4J
#Carbon server where data should be stored for graphite to show - El servidor carbon on s'han de guardar les dades que mostra el graphite
carbon_server=graphite.domain.tld
# Tree structure where we want information to be stored - L'estructura de l'arbre on volem que es guardin les dades a graphite.
tree=servers
now=date +%s
host=${1:-localhost}
#Number of connections - Numero de connexions
if [ $host == "localhost" ];then
connections=netstat -tn|grep ESTABLISHED|awk '{print $4}'|grep 9160|wc -l
else
connections=ssh $host netstat -tn|grep ESTABLISHED|awk '{print $4}'|grep 9160|wc -l
fi
data="$tree.$host.cassandra.connections $connections $nown"
#Tasks in ReadStage - Tasques en ReadStage
data="$data curl http://$host:8081/mbean?objectname=org.apache.cassandra.request%3Atype%3DReadStage -s |egrep "CompletedTasks|PendingTasks|ActiveCount"|cut -d">" -f8|cut -d"<" -f1|awk -v tree=$tree -v now=$now -v host=$host '(NR == 1) {printf("%s.%s.cassandra.ReadStage.ActiveCount %s %s\n",tree, host, $0, now)} (NR == 2) {printf("%s.%s.cassandra.ReadStage.CompletedTasks %s %s\n",tree, host, $0, now)} (NR ==3) {printf("%s.%s.cassandra.ReadStage.PendingTasks %s %s\n",tree, host, $0, now)}'"
#Tasks in MutationStage - Tasques en MutationStage (writes)
data="$data curl http://$host:8081/mbean?objectname=org.apache.cassandra.request%3Atype%3DMutationStage -s |egrep "CompletedTasks|PendingTasks|ActiveCount"|cut -d">" -f8|cut -d"<" -f1|awk -v tree=$tree -v now=$now -v host=$host '(NR == 1) {printf("%s.%s.cassandra.MutationStage.ActiveCount %s %s\n",tree,host, $0, now)} (NR == 2) {printf("%s.%s.cassandra.MutationStage.CompletedTasks %s %s\n",tree,host, $0, now)} (NR ==3) {printf("%s.%s.cassandra.MutationStage.PendingTasks %s %s\n",tree, host, $0, now)}'"
#Tasks in GossipStage - Tasques en GossipStage (comunicacio interna entre cassandras)
data="$data curl http://$host:8081/mbean?objectname=org.apache.cassandra.internal%3Atype%3DGossipStage -s |egrep "CompletedTasks|PendingTasks|ActiveCount"|cut -d">" -f8|cut -d"<" -f1|awk -v tree=$tree -v now=$now -v host=$host '(NR == 1) {printf("%s.%s.cassandra.GossipStage.ActiveCount %s %s\n",tree, host, $0, now)} (NR == 2) {printf("%s.%s.cassandra.GossipStage.CompletedTasks %s %s\n",tree, host, $0, now)} (NR ==3) {printf("%s.%s.cassandra.GossipStage.PendingTasks %s %s\n",tree, host, $0, now)}'"
#Compaction tasks - Tasques de compactacio
data="$data curl http://$host:8081/mbean?objectname=org.apache.cassandra.db%3Atype%3DCompactionManager -s|egrep "CompletedTasks|PendingTasks"|cut -d">" -f8|cut -d"<" -f1|awk -v tree=$tree -v now=$now -v host=$host '(NR == 1) {printf("%s.%s.cassandra.Compaction.CompletedTasks %s %s\n",tree, host, $0, now)} (NR == 2) {printf("%s.%s.cassandra.Compaction.PendingTasks %s %s\n",tree, host, $0, now)}'"
#Operation Latency - Latencia d'operacions
data="$data curl http://$host:8081/mbean?objectname=org.apache.cassandra.db%3Atype%3DStorageProxy -s |egrep "RecentRangeLatencyMicros|RecentReadLatencyMicros|RecentWriteLatencyMicros"|cut -d">" -f8|cut -d"<" -f1|awk -v tree=$tree -v now=$now -v host=$host '(NR == 1) {printf("%s.%s.cassandra.Latency.Range %s %s\n",tree, host, $0, now)} (NR == 2) {printf("%s.%s.cassandra.Latency.Read %s %s\n",tree,host, $0, now)} (NR ==3) {printf("%s.%s.cassandra.Latency.Write %s %s\n",tree,host, $0, now)}'"
#Heap and non-heap memory - Us de Memoria Heap i NoHeap
data="$data curl http://$host:8081/mbean?objectname=java.lang%3Atype%3DMemory -s|grep HeapMemoryUsage|awk -F"max=" '{print $2}'|cut -d"}" -f1|sed -e 's/, used=/n/g'|awk -v tree=$tree -v now=$now -v host=$host '(NR == 1) {printf("%s.%s.cassandra.internals.MaxJavaHeap %s %s\n",tree, host, $0, now)} (NR == 2) {printf("%s.%s.cassandra.internals.JavaHeapUsed %s %s\n",tree, host, $0, now)} (NR ==3) {printf("%s.%s.cassandra.internals.MaxJavaNoHeap %s %s\n",tree, host, $0, now)} (NR == 4) {printf("%s.%s.cassandra.internals.JavaNoHeapUsed %s %s\n",tree, host, $0, now)}'"
#Number of GarbageCollections - Numero de GarbageCollections
data="$data curl http://$host:8081/mbean?objectname=java.lang%3Atype%3DGarbageCollector%2Cname%3DConcurrentMarkSweep -s| grep CollectionCount|cut -d">" -f8|cut -d"<" -f1|awk -v tree=$tree -v now=$now -v host=$host '{printf("%s.%s.cassandra.internals.GarbageCollections %s %s\n",tree, host, $0, now)}'"
echo $data
echo -e $data|nc -w 5 $carbon_server 2003
exit $?
Si, és força lleig. Això en python o perl seria molt més maco. Però com sempre, comença amb una cosa petita que es fa amb una crida senzilla, i després va creixent i creixent fins que ens trobem amb això... Que hi farem. Ja intentaré fer una versió millorada.
Un cop tenim aquests valors al graphite els hem de donar sentit. Hi ha valors que són útils tal i com els recollim, com per exemple el número de connexions o les operacions pendents, però a tots els que siguin acumulatius, és a dir, el número de GarbageCollections o totes les CompletedTasks (tant les de Compaction com les ReadStage, WriteStage, GossipStage) els haurem d'aplicar la funció derivative per saber quantes es fan per interval de temps i detectar així increments inusuals.
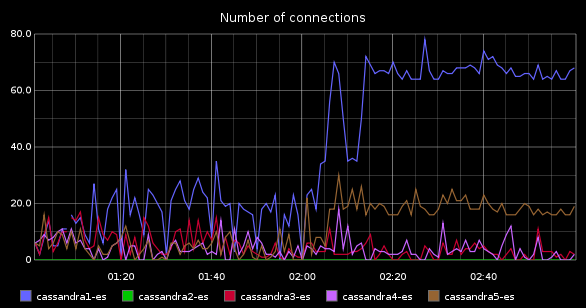
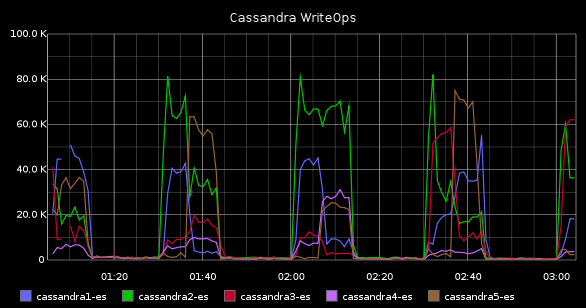
I finalment, si fem un dashboard on els posem tots, podrem esbrinar en un cop d'ull si els problemes que han aparegut a la nostra aplicació tenen a veure amb el cassandra o en realitat és innocent. Un possible dashboard podria ser com aquest:
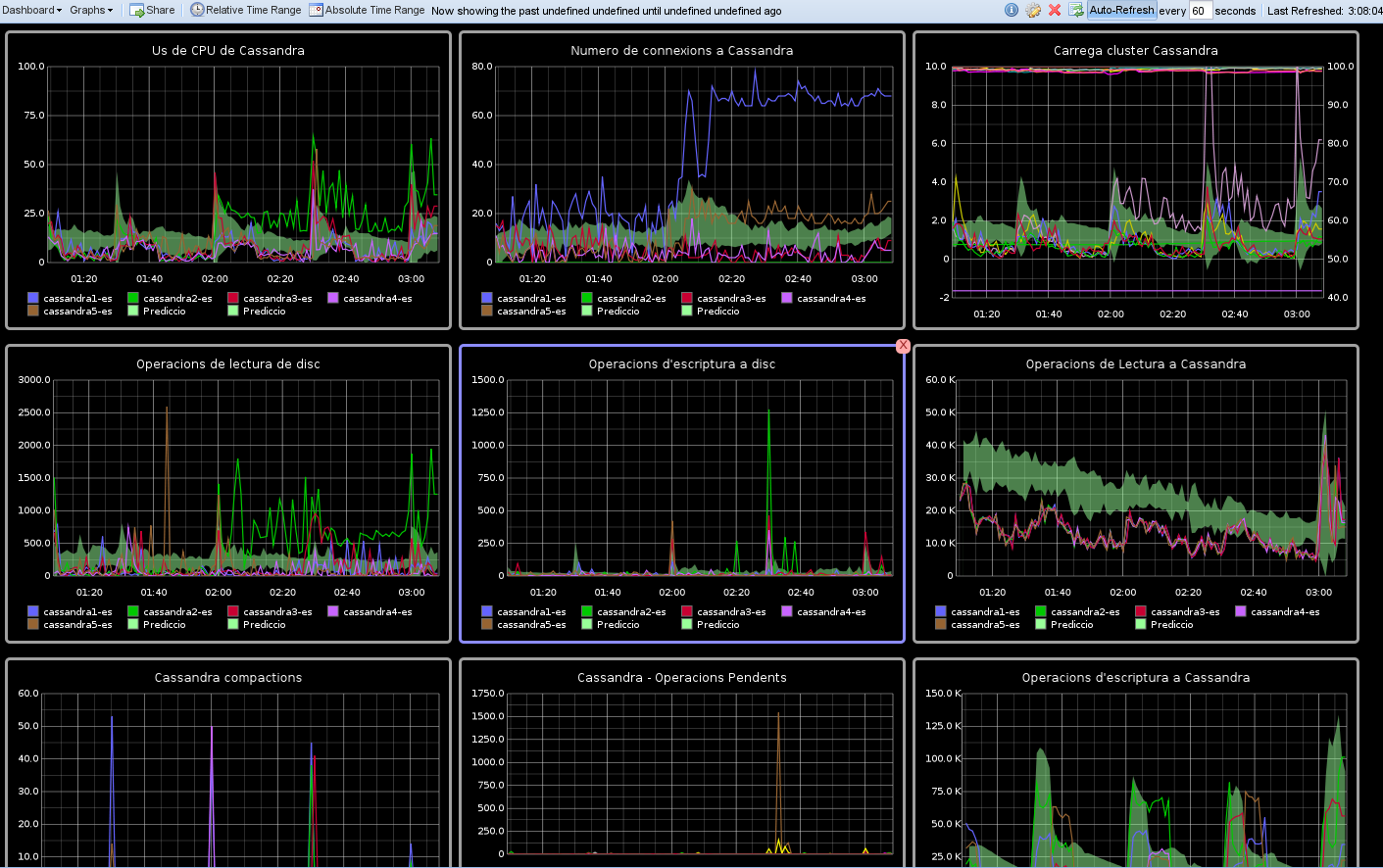
I fins ara res més. En un futur faré la segona part on inclouré la informació sobre les columnfamilies.
Bibliografia:
- http://www.manageengine.com/products/applications_manager/cassandra-monitoring.html
- http://jonathanhui.com/cassandra-performance-tuning-and-monitoring
- http://www.datastax.com/docs/1.1/operations/monitoring
- http://wiki.apache.org/cassandra/Operations#Monitoring
- http://suniluiit.wordpress.com/2011/02/21/apache-cassandra-monitoring-through-hyperic-hq/