When we have lots of servers and we need to execute jobs regularly, we rapidly outgrow cron, because the information is spreaded along all the servers and you don’t have an easy way to, for instance, check the execution result of a task in all servers, or what tasks were running between 16:33 and 16:36, or to find the less busy spot to schedule a new job in your architecture. And many other things.
To centralize this information there are some alternatives. Recently, the nerds in airbnb have released chronos and it seems a good way to go, but I’ve been using rundeck for a while and I’m very happy with it.
It works in a simple way: it’s a java daemon with a grails interface for the web access, and a quartz scheduler for event scheduling. This server makes ssh connections to the remote servers to execute the configured tasks. This allows us to have a centralized cron (our original intent with this article), but we can also use it as a centralized sudo (we can decide which user can run which command in which servers, all from the web console, without giving away ssh access at all), and also allows us to have a centralized shell, so we can run a command in several servers at the same time, like terminator or more like fabric .
Now that we’ve introduced rundeck, let’s start installing in our RedHat. We must have in mind that rundeck runs with the rundeck user, so it’s unprivileged, so it can’t use port 80. To make it work for this example, we will proxypass with apache. First of all we install apache (obvious):
# yum install httpd
Then we edit /etc/httpd/conf/httpd.conf file and add two lines:
ProxyPass / http://localhost:4440/
ProxyPassReverse / http://localhost:4440/
This way apache will forward al the connexions in port 80 to port 4440, where rundeck is awaiting.
Now for the data. Rundeck uses a database file by default (formerly it used hsql, now it uses h2). This is fine, but at some point we will outgrow it. To avoid that, we will use a mysql database. First we install it (obvious, again):
yum install mysql mysqld
chkconfig mysqld on
We can tune it editing my.cnf with the usual (default-storage-engine=innodb, innodb_file_per_table, etc, etc). After that we need to create a database for rundeck, and a user with permissions:
[[email protected] rundeck]# mysql -p
Enter password:
Your MySQL connection id is 18536
Server version: 5.5.30 MySQL Community Server (GPL) by Remi
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.
mysql> create database rundeck;
Query OK, 1 row affected (0.00 sec)
mysql> grant all on rundeck.* to 'rundeck'@'localhost' identified by 'password';
Query OK, 0 rows affected (0.00 sec)
mysql> quit
Bye
Now we install rundeck, first the official application repo and then the program itself:
wget http://repo.rundeck.org/latest.rpm
rpm -Uvh latest.rpm
yum install rundeck
And we configure the database in the file /etc/rundeck/rundeck-config.properties, commenting out the existing line and adding three more:
#dataSource.url = jdbc:h2:file:/var/lib/rundeck/data/rundeckdb
dataSource.url = jdbc:mysql://localhost/rundeck
dataSource.username = rundeck
dataSource.password = password
Now we start it
/etc/init.d/rundeck start
We can check it’s using the database because it will create its tables:
[[email protected] rundeck]# mysql -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or g.
Your MySQL connection id is 31
Server version: 5.5.30 MySQL Community Server (GPL) by Remi
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.
mysql> use rundeck
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+----------------------------+
| Tables_in_rundeck |
+----------------------------+
| auth_token |
| base_report |
| execution |
| node_filter |
| notification |
| rdoption |
| rdoption_values |
| rduser |
| report_filter |
| scheduled_execution |
| scheduled_execution_filter |
| workflow |
| workflow_step |
| workflow_workflow_step |
+----------------------------+
14 rows in set (0.00 sec)
We have our service running. Now we must export our public ssh key to gain access to run commands on the remote servers:
[[email protected] .ssh]# su - rundeck
[[email protected] ~]$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/var/lib/rundeck/.ssh/id_rsa): project1_rsa
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in project1_rsa.
Your public key has been saved in project1_rsa.pub.
The key fingerprint is:
f6:be:e5:0r:b2:zd:9b:89:1e:2c:6f:fc:od:e5:a5:00 [email protected]
[[email protected] ~]$ ssh-copy-id -i /var/lib/rundeck/.ssh/project1_rsa [email protected]
[email protected]'s password:
0
The authenticity of host 'server2 (222.333.444.555)' can't be established.
RSA key fingerprint is b6:6z:34:2o:04:2f:j1:71:1e:12:b3:fd:e2:f2:79:cf.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'server2-es,222.333.444.555' (RSA) to the list of known hosts.
Now try logging into the machine, with "ssh [email protected]'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[[email protected] ~]$ ssh [email protected] whoami
user
Stay with me, we’re almost there. Now we can log in the web with user admin and password admin:
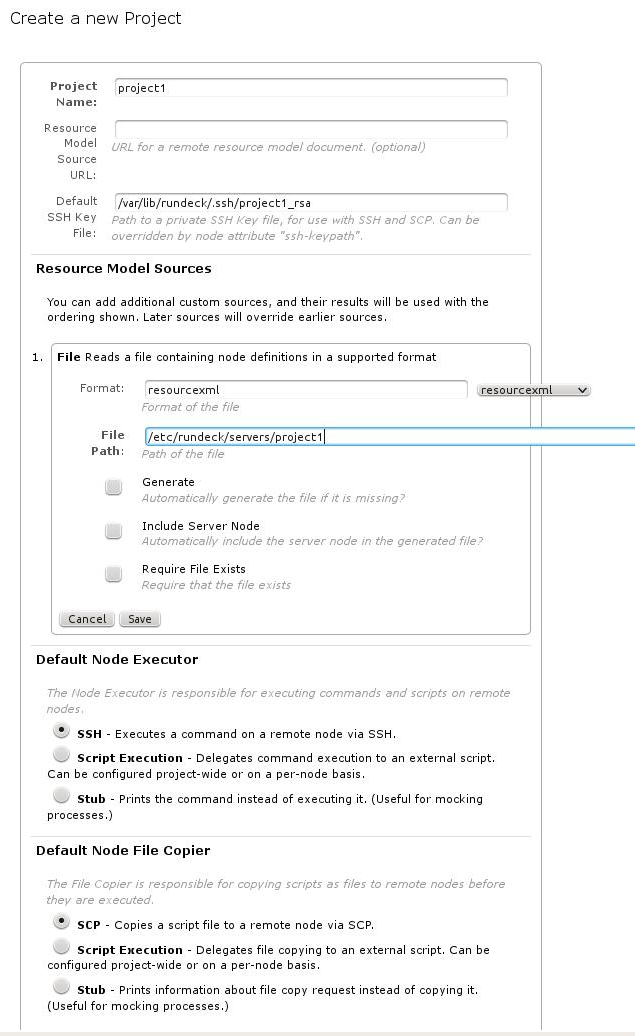
The first thing is to create a project, and here we put the former information
When the project is generated, we will land on the project page, where we can run local commands:
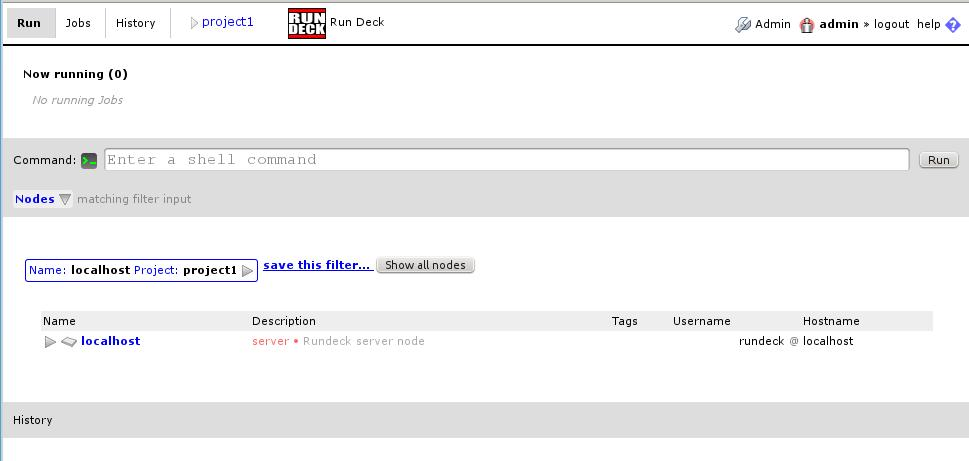
Now for the last step, adding the remote servers. As we configured in the project creation, we will put them in the file /etc/rundeck/servers/project1 in xml format:
Once we add them, we can use them without restarting, just clicking “show all nodes” button:
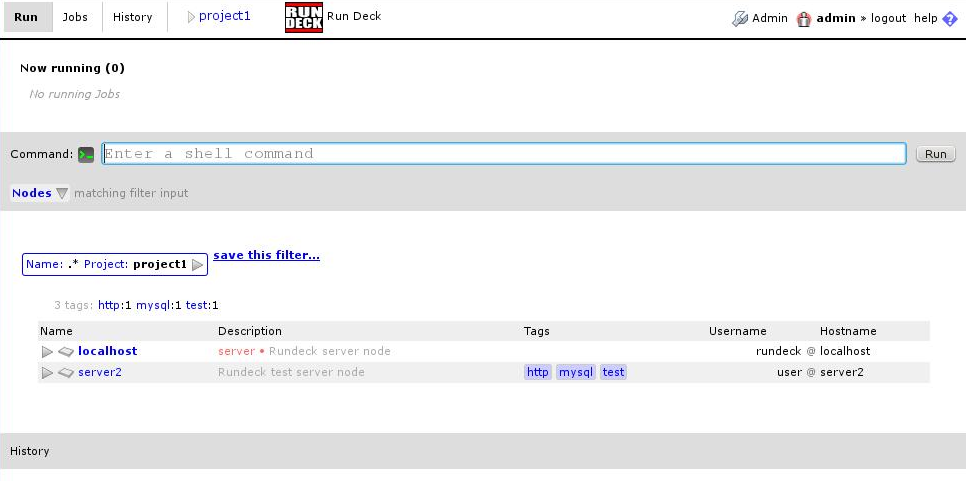
And that’s it. From this point on it’s very easy. In this console we can run remote commands, and in the “jobs” tab we can create jobs.
There are some more things we can configure. For instance, we can change the rundeck logo to put our company’s logo in the file /etc/rundeck/rundeck-config.properties
rundeck.gui.title = Programador de tareas de la nostra empresa
rundeck.gui.logo = logo.jpg
rundeck.gui.logo-width = 68
rundeck.gui.logo-heigh = 31
Or if we want to create more users, or to change admin password (you should change it!) we will add them to /etc/rundeck/realm.properties
admin: MD5:5a527f8fegf916h8485dj6681ff8d7a6a,user,admin,architect,deploy,build
newuser: MD5:0cddh73e3g6108a7fh5f3716a9jf97and4e56ff,user
And permissions are managed in the file /etc/rundeck/admin.aclpolicy.
With all this we are ready to start playing with rundeck.